I am learning the model in A5 of Stanford CS224n and I am also a beginner for PyTorch. So I hope I could fully understand the code. All the code below are typed manually with added comments and it may have some typo. Please check Stanford CS224n website for the original code. Even typing is time consuming, it makes me think about the question which I would not realize if I just read the code. Currently I don’t think it is well organized but I am keep updating and will organize it better when I totally finish this assignment.
attention.py
import math
import logging
import torch
import torch.nn as nn
from torch.nn import functional as F
logger = logging.getLogger(__name__)
Functions used in next class:
-
nn.linear:torch.nn.Linear(in_features, out_features, bias=True)Applies a linear transformation to the incoming data by \(Y=X*W^T\) where the dimension of \(W\) is \((out\_features,in\_features)\) , the dimension of \(X\) is \((N,*,in\_features)\) and the dimension of \(Y\) is \((N,*,out\_features)\). It can be also considered as implementing \(Y=W\times X\) and the dimension of \(W\) is \((in\_features,out\_features)\).
-
torch.tril:torch.tril(input, diagonal=0, *, out=None) → TensorReturns the lower triangular part of the matrix (2-D tensor)
-
torch.viewandtorch.reshapeare both used to reshape tensors but there are some differences between them:-
torch.viewcreates a view of the original tensor and it will share memory with the original tensor. This means if you change the original tensor, the reshaped tensor will change too. Whiletorch.reshapewill create a new tensor with assigned shape and own memory space. -
torch.viewcan only operate on contiguous tensor whiletorch.reshapecan operate on both contiguous and non-contiguous tensor. For example,>>> z = torch.zeros(3, 2) >>> y = z.t() >>> y.size() torch.Size([2, 3]) >>> y.view(6) Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: invalid argument 2: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Call .contiguous() before .view(). >>> z = torch.zeros(3, 2) >>> y = z.reshape(6) >>> x = z.t().reshape(6) >>> z.fill_(1) tensor([[1., 1.], [1., 1.], [1., 1.]]) >>> y tensor([1., 1., 1., 1., 1., 1.]) >>> x tensor([0., 0., 0., 0., 0., 0.])
-
-
register_buffer(name,tensor,persistent=True)is a function undernn.Moduleand name is the name of buffer and tensor is the buffer to be registered.Add buffers to the module. It is like setting
self.name = tensor. However, the registered tensor won’t be considered as a model parameter. For example, BatchNorm’srunning_meanis not a parameter but is part of the module’s state. Ifpersistent==True, the buffer will be saved alongside parameters and be a part of this module’sstate_dict, while a non-persistent buffer will not be a part of this module’sstate_dict. -
masked_fill(mask, value) → TensorFill elements of self tensor with value where mask is True and the shape of mask must be broadcastable with the shape of tensor who calls this function.
class CausalSelfAttention(nn.Module):
"""
A vanilla multi-head maksed self-attention layer with a projection at the end.
I believe I could have just used torch.nn.MultiheadAttention but their documentation is all but absent and code ugly so I don't trust it, rolling my own here.
"""
def __init__(self,config):
super().__init__() # yz: inheriate the init function in nn.Module
# key, query, value projections for all heads
self.key = nn.Linear(config.n_embd,config.n_embd)
self.query = nn.Linear(config.n_embd,config.n_embd)
self.value = nn.Linear(config.n_embd,config.n_embd)
# regularization
self.attn_drop = nn.Dropout(config.attn_pdrop)
self.resid_drop = nn.Dropout(config.resid_pdrop)
# output projection
self.proj = nn.Linear(config.n_embd,config.n_embd)
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("mask",torch.tril(
torch.ones(config.block_size,config.block_size))
.view(1,1,config.block_size,block_size))
self.n_head = config.n_head
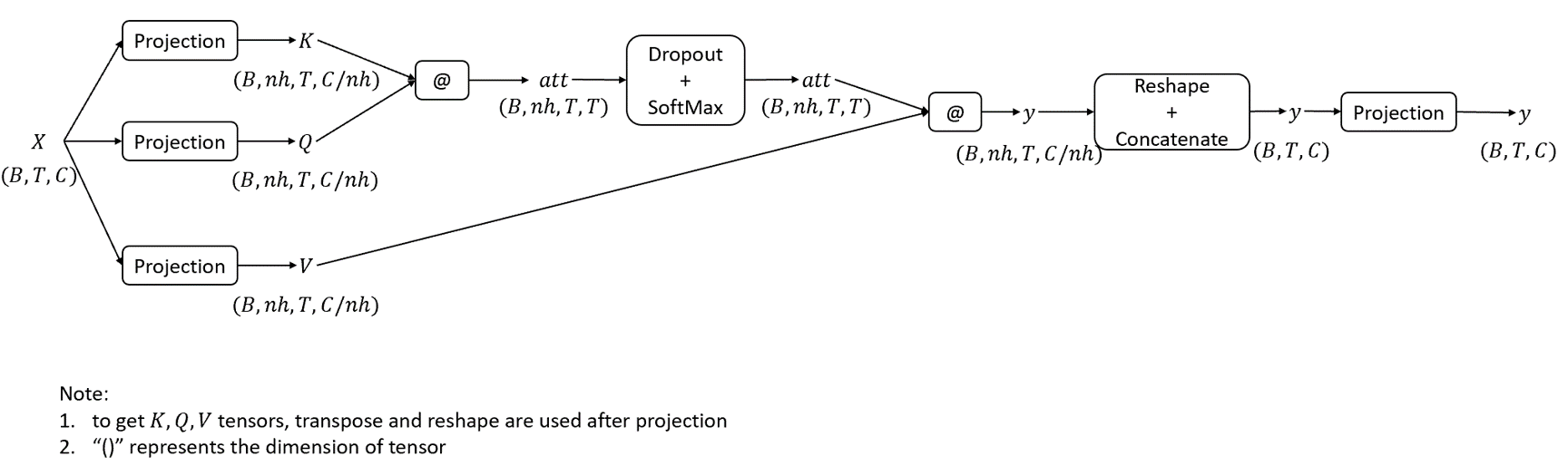
def forward(self,x,layer_past=None):
B,T,C = x.size()
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
k = self.key(x).view(B,T,self.n_head,C//self.n_head).transpose(1,2) # (B,nh,T,C/nh)
q = self.query(x).view(B,T,self.n_head,C//self.n_head).transpose(1,2) #(B,nh,T,C/nh)
v = self.value(x).view(B,T,self.n_head,C//self.n_head).transpose(1,2) # (B,nh,T,C/nh)
# causal self-attention; self-attend: (B,nh,T,hs) X (B,nh,hs,T) -> (B,nh,T,T)
att = (q @ k.transpose(-2,-1))*(1.0/math.sqrt(k.size(-1))) #yz: WHY?????????
att = att.masked_fill(self.mask[:,:,:T,:T]==0,-1e10)
att = F.softmax(att,dim=-1)
att = self.attn_drop(att)
y = att @ v
y = y.transpose(1,2).contiguous().view(B,T,C)
# output projection
y = self.resid_drop(self.proj(y))
return y
self-attention
Qualitatively speaking, attention is used to produce features based on the similarity between keys and query. Self-attention means the queries, keys and values come from the same source which is X (input data).
Note:
-
The dimension of output from self-attention block is \((B,T,C)\) which is the same as that of input.
-
C is equal to
config.n_embdwhich is the size of embeddings for each word. Is that always the case ?
Functions used in the next class
-
torch.nn.init.uniform_(tensor, a=0.0, b=1.0)Fills the input Tensor with values drawn from the uniform distribution \(U(a,b)\).
"""
Write your SynthesizerAttention below.
Hint: paste over the CausalSelfAttention above and modify it minimally.
"""
class SynthesizerAttention(nn.Module):
def __init__(self,config):
super().__init__()
assert config.n_embd % config.n_head = 0
# NEW leanable weights
self.w1 = nn.Linear(config.n_embd,config.n_embd)
self.w2 = nn.Parameter(torch.zeros(config.n_embd // config.n_head,config.block_size-1))
self.b2 = nn.Parameter(torch.zeros(config.block_size-1))
# value projection
self.value = nn.Linear(config.n_embd,config.n_embd)
# regularization
self.attn_drop = nn.Dropout(config.attn_pdrop)
self.resid_drop = nn.Dropout(config.resid_pdrop)
# output projection
self.proj = nn.Linear(config.n_embd,config.n_embd)
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("mask",torch.tril(
torch.ones(config.block_size,config.block_size))
.view(1,1,config.block_size,block_size))
self.n_head = config.n_head
self.block_size = config.block_size
nn.init.uniform_(self.w2, -0.001,0.001)
def forward(self,x,layer_pass=None):
Model.py
"""
GPT model:
- the initial stem consists of a combination of token encoding and a positional encoding
- the meat of it is a uniform sequence of Transformer blocks
- each Transformer is a sequential combination of a 1-hidden-layer MLP block and a self-attention block
- all blocks feed into a central residual pathway similar to resnets
- the final decoder is a linear projection into a vanilla Softmax classifier
"""
import math
import torch
import torch.nn as nn
from torch.nn import functional as F
import attention
Functions in the next class:
-
setattr(object,name,value)is used to set the attribute named by “name” for object named by “object” as “value”. For exampleclass Person: name = 'Adam' p = Person() print('Before modification:', p.name) # setting name to 'John' setattr(p, 'name', 'John') print('After modification:', p.name) -
torch.nn.LayerNorm(normalized_shape, eps=1e-05,elementwise_affine=True)Applies Layer Normalization over a mini-batch of inputs. The mean and standard-deviation are calculated separately over the last certain number of dimensions which have to be of the shape specified by
normalized_shape. Layer normalization is computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case.
class GPTConfig:
""" base GPT config, paras common to all GPT versions """
embd_pdrop = 0.1
resid_pdrop = 0.1
attn_pdrop = 0.1
additive = False # yz: a flag to indicate which attention to use
def __init__(self.vocab_size,block_size, **kwargs):
self.vocab_size = vocab_size
self.block_size = block_size
for k,v in kwargs.items():
setattr(self,k,v)
class GPT1Config(GPTConfig):
""" GPT-1 like network roughly 125M params """
n_layer = 12
n_head = 12
n_embd = 768
class Block(nn.Module):
""" an unassuming Transformer block """
def __init__(self,config):
super().__init__()
self.ln1 = nn.LayerNorm(config.n_embd)
self.ln2 = nn.LayerNorm(config.n_embd)
if config.additive:
self.attn = attention.AdditiveSelfAttention(config)
else:
self.attn = attention.CausalSelfAttention(config)
self.mlp = nn.Sequential(
nn.Linear(config.n_embd,4*config.n_embd),
nn.GELU(),
nn.Linear(4*config.n_embd,config.n_embd),
nn.Dropout(config.n_embd,config.n_embd)
)
def forward(self,x):
x = x + self.attn(self.ln1(x))
x = x + self.mlp(self.ln2(x))
return x
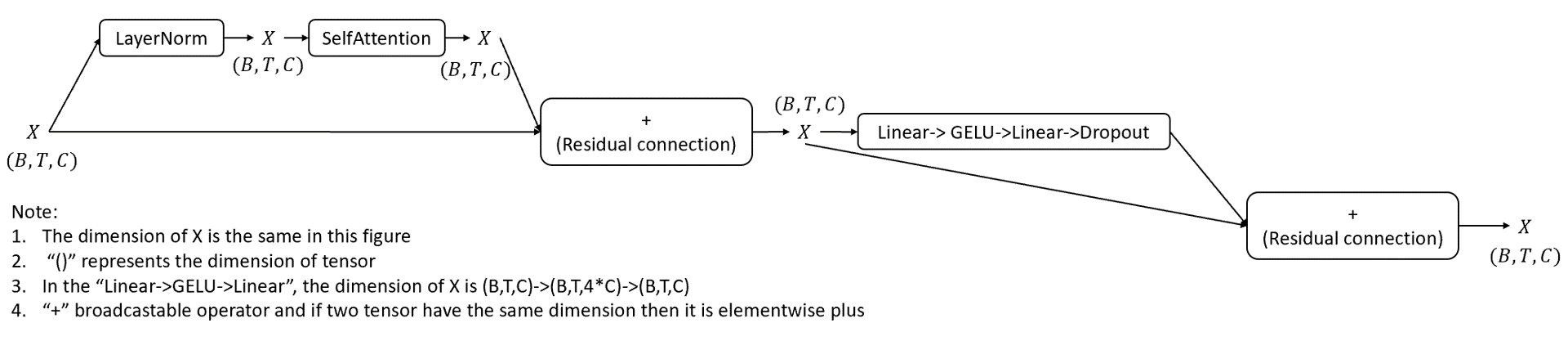
Note:
- The dimension of output from block is \((B,T,C)\) which is the same as that of input.
Functions in the next class
-
apply(fn)Applies
fnrecursively to every submodule (as returned by.children()) as well as self. Typical use includes initializing the parameters of a model.
class GPT(nn.Module):
""" the full GPT language model, with a context size of block_size """
def __init__(self,config):
super().__init__()
# input embedding stem
self.tok_emb = nn.Embedding(config.vocab_size,config.n_embd)
self.pos_emb = nn.Parameters(torch.zeros(1,config.block_size,config.n_embd))
self.drop = nn.Dropout(config.embd_pdrop)
# transformer
self.blocks = nn.Sequential(*[Block(config) for _ in range(config.n_layer)])
# decoder head
self.ln_f = nn.LayerNorm(config.n_embd)
self.head = nn.Linear(config.n_embd,config.vocab_size,bias=False)
self.block_size = config.block_size
self.apply(self._init_weights)
print("number of parameters:{}".format(sum(p.numel() for p in self.parameters())))
def _init_weights(self,module):
if isinstance(module,(nn.Linear,nn.Embedding)):
module.weight.data.normal_(mean=0.0,std=0.02)
if isinstance(module,nn.Linear) and module.bias is not None:
module.bias.data.zero_()
elif isinstance(module,nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def get_block_size(self):
return self.block_size
def forward(self,idx,targets=None):
b,t = idx.size()
assert t <= self.block_size, "Cannot forward, model block size is exhausted. "
# forward the GPT model
token_embeddings = self.tok_emb(idx)
position_embeddings = self.pos_emb[:,:t,:]
x = self.drop(token_embeddings + position_embeddings)
x = self.blocks(x)
x = self.ln_f(x)
logits = self.head(x)
# if we are given some desired targets also calculate the loss
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1,logits.size(-1)),targets.view(-1),ignore_index=0)
return logits, loss

dataset.py
import random
import torch
from torch.utils.data import Dataset
import argparse
"""
The input-output pairs (x, y) of the NameDataset are of the following form:
x: Where was Khatchig Mouradian born?⁇Lebanon⁇□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□
y: □□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□⁇Lebanon⁇□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□
x: Where was Jacob Henry Studer born?⁇Columbus⁇□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□
y: □□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□⁇Columbus⁇□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□
Using the PAD_CHAR characters in y before the ⁇[place] keeps the trainer from
optimizing the model to predict the question, "Where was...".
Note that the NameDataset should take the pretraining_dataset defined in run.py
as an input. This is to allow the vocab specification of the NameDataset to be
the same as that of the pretraining dataset.
You don't need to implement anything in NameDataset.
"""
class NameDataset(Dataset):
def __init__(self, pretraining_dataset,data):
self.MASK_CHAR = u"\u2047" # the doublequestionmark character,for mask
self.PAD_CHAR = u"\u25A1" # the empty square character, for pad
self.itos = pretraining_dataset.itos
self.stoi = pretraining_dataset.stoi
self.block_size = pretraining_dataset.block_size
self.data = list(data.encode('utf-8').decode('ascii',errors='ignore').split('\n'))
def __len__(self):
return len(self.data) - 1 # yz: why -1 ??
def __getitem__(self,idx):
inp,oup = self.data[idx].split('\t')
class CharCorruptionDataset(Dataset):
def __init__(self,data,block_size):
self.MASK_CHAR = u"\u2047"
self.PAD_CHAR = u"\u25A1"
chars = list(sorted(list(set(data)))) # yz: every elemet is just a char
assert self.MASK_CHAR not in chars
assert self.PAD_CHAR not in chars
chars.insert(0,self.MASK_CHAR)
chars.insert(0,self.PAD_CHAR)
self.stoi = {ch:i for i,ch in enumerate(chars)}
self.itos = {i:ch for i,ch in enumerate(chars)}
data_size, vocab_size = len(data), len(chars)
print('data has %d characters, %d unique.' %(data_size,vocab_size))
self.block_size = block_size
self.vocab_size = vovab_size
self.data = data.split('\n')
def __len__(self):
return len(self.data)
def __gititem__(self):
pass
train.py
"""
Simple training loop; Boilerplate that could apply to any arbitrary neural network,
so nothing in this file really has anything to do with GPT specifically.
We suggest not changing anything in this file.
"""
import math
import logging
from tqdm import tqdm
import numpy as np
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import LambdaLR
from torch.utils.data.dataloader import DataLoader
logger = logging.getLogger(__name__)
Functions used in next class
-
torch.cudaThis package adds support for CUDA tensor types, that implement the same function as CPU tensors, but they utilize GPUs for computation.
–
torch.cuda.is_available()checks if your system supports CUDA–
torch.cuda.current_device()returns the index of a currently selected device -
torch.nn.DataParallel(module,device_ids)Implements data parallelism. Splitting the input across the specified devices by chunking in the batch dimension and other objects will be copied once per device. During the backward pass, gradients from each replica are summed into the original module.
-
nn.module.named_parameters(prefix='', recurse=True)Returns an iterator over module parameters, yielding both the name of the parameters as well as the parameter itself.
-
torch.optim.AdamW(params, lr = 0.001, betas = (0.9,0.999),eps = 1e-8...) – params (iterable) – iterable of parameters to optimize or dicts defining parameter groups
– lr (float, optional) – learning rate (default: 1e-3)
– betas (Tuple**[float,float], optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
-
torch.nn.Module.train(mode=True)Sets the module in training mode which only have effects on certain modules like Dropout, BathNorm, etc.
-
torch.utils.data.DataLoader(dataset,batch_size=1,shuffle=False,...)Combines a dataset and a sampler and provides an iterable over the given dataset.
-
torch.Tensor.item()to get a Python number from a tensor containing a single value -
model = GPT(config)thenmodel(x,y)will callnn.module.__call__()in which will further callforward(x,y)in GPT model. -
torch.nn.Module.zero_grad()to set all parameters gradients as zero -
loss.backward()computes \(dloss/dx\) for every parameter x which has
requires_grad = True -
optimizer.param_groupsis a list of dicts. Each dict represents the parameters optimized using same setting.
class TrainerConfig:
max_epochs = 10
batch_size = 64
learning_rate = 3e-4
betas = (0.9,0.95)
grad_norm_clip = 1.0
weight_decay = 0.1 # ponly applied on matmul weights
# learning rate decay params: linear warmup followed by cosine decay to 10% of original
lr_decay = False
warmup_tokens = 375e6 # these two numbers come from GPT-3 paper but may not be good defaults else where
final_tokens = 260e9
# checkpoint settings
ckpt_path = None
num_workers = 0 # for DataLoader
def __init__(self,**kwargs):
for k,v in kwargs.items():
setattr(self,k,v)
class Trainer:
def __init__(self,model,train_dataset,test_dataset,config):
self.model = model
self.train_dataset = train_dataset
self.test_dataset = test_dataset
self.config = config
self.device = 'cpu'
# yz: setting this if training by GPU
if torch.cuda.is_available():
self.device = torch.cuda.current_device()
self.model = torch.nn.DataParallel(self.model).to(self.device)
def save_checkpoint(self):
if self.config.ckpt_path is not None:
ckpt_model = self.model.module if hasattr(self.model,"module") else self.model
logger.info("saving %s", self.config.ckpt_path)
torch.save(ckpt_model.state_dict(),self.config.ckpt_path)
def train(self):
model, config = self.model, self.config
# create the optimizer
no_decay = ["bias","LayerNorm.weight"] # yz: which is not considered in regularization term of loss function
params_decay = [p for n,p in model.named_parameters() if not any(nd in n for nd in no_decay)]
params_nodecay = [p for n,p in model.named_parameters() if any(nd in n for nd in no_decay)]
optim_groups = [
{"params":params_decay,"weight_decay": config.weight_decay},
{"params":paras_nodecay,"weight_decay": 0.0},
]
optimizer = optim.AdamW(optim_groups,lr = config.learning_rate, betas = config.betas)
def run_epoch(split):
is_train = split == 'train'
model.train(is_train) # set the model in training mode
data = self.train_dataset if is_train else self.test_dataset
loader = DataLoader(data, batch_size = config.batch_size,
num_workers = config.num_workers)
losses = []
pbar = tqdm(enumerate(loader),total = len(loader)) if is_train else enumerate(loader)
for it, (x,y) in pbar:
# place data on the correct device
# the dimension of x,y is the same which are both (batch.size,sentence length)
x = x.to(self.device)
y = y.to(self.device)
# forward the model
with torch.set_grad_enabled(is_train):
logits,loss = model(x,y) # yz: what is dimension of loss????
loss = loss.mean() # collapse all losses if they are scattered on nultiple gpus
losses.append(loss.item())
if is_train:
# backprop and update the parameters
model.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(),
config.grad_norm_clip)
optimizer.step()
# decay the learning rate based on our progress
if config.lr_decay:
self.tokens += (y >= 0).sum() # number of tokens processed this step
if self.tokens < config.warmup_tokens:
# linear warmup
lr_mult = float(self.tokens)/float(
max(1,config.warmup_tokens))
else:
# cosine learning rate decay
progress = float(self.tokens - config.warmup_tokens)/float(max(1,config.final_tokens - config.warmup_tokens))
lr_mult = max(0.1,0.5*(1.0+math.cos(math.pi*progress)))
lr = config.learning_rate * lr_mult
for param_group in optimizer.param_groups:
param_group['lr'] = lr
else:
lr = config.learning_rate
# report progress
pbar.set_description(f"epoch {epoch+1} iter {it}: train loss {loss.item():.5f}. lr {lr:e}")
if not is_train:
logger.info("test loss: %f",np.mean(losses))
self.tokens = 0
for epoch in range(config.max_epochs):
run_epoch('train')
if sef.test_dataset is not None:
run_epoch('test')
self.save_checkpoint()
utils.py
Functions used in the next block
-
torch.multinomial(input,num_samples,replacement=False...)sample
num_samplesfrom the last dimension of input based on its probabilities. Ifinputis a vector,outis a vector of sizenum_samples. if the dimension of input is \((B,V)\), then the dimension of output is \((B,num\_samples)\).
""" Utilities; we suggest changing none of these functions
but feel free to add your own.
"""
import random
import numpy as np
import torch
import torch.nn as nn
from torch.nn import functional as F
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def top_k_logits(logits,k)
v,ix = torch.topk(logits,k) #
out = logits.clone()
out[out<v[:,[-1]]] = -float('Inf')
return out
@torch.no_grad()
def sample(model,x,steps,temperature=1.0,sample=False,top_k=None):
"""
take a conditioning sequence of indices in x (of shape (b,t)) and predict the next token in
the sequence, feeding the predictions back into the model each time. Clearly the sampling
has quadratic complexity unlike an RNN that is only linear, and has a finite context window
of block_size, unlike an RNN that has an infinite context window.
"""
block_size = model.get_block_size()
model.eval() #evaluation mode
for k in range(steps):
x_cond = x if x.size(1) <= block_size else x[:,-block_size]
logits,_ = model(x_cond) # yz: logits dimension is (B,min(T,block_size),V)
# pluck the logits at the final step and scale by temperature
# yz: why scale??
logits = logits[:,-1,:]/temperature # yz: logits dimension is (B,V)
# optionally crop probabilities to only the top k options
if top_k is not None:
logits = top_k_logits(logits,top_k)
# apply softmax to convert to probabilities
probs = F.softmax(logits,dim=-1) #yz: dimension is (B,V)
# sample from the distribution or take the most likely
if sample:
ix = torch.multinomial(probs,num_samples=1) # yz: ix dimension is (B)
else:
_,ix = torch.topk(probs,num_samples=1)
# append to the sequence and continue
x = torch.cat((x,idx),dim=1)
return x
def evaluate_places(filepath,predicted_places):
"""
Computes percent of correctly predicted birth places.
Arguments:
filepath: path to a file with our name, birth place data.
predicted_places: a list of strings representing the
predicted birth place of each person.
Returns: (total, correct), floats
"""
with open(filepath) as fin:
lines = [x.strip().split('\t') for x in fin]
if len(lines[0]) == 1:
print('No gold birth palces provided; returning (0,0)')
return (0,0)
true_places = [x[1] for x in lines]
total = len(true_places)
assert total == len(predicted_places)
correct = len(list(filter(lambda x: x[0]==x[1],
zip(true_places,predicted_places))))
return (float(total),float(correct))
run.py
import numpy as np
import torch
import torch.nn as nn
from tqdm import tqdm
from torch.nn import functional as F
import random
import argparse
random.seed(0)
import dataset
import model
import trainer
import utils
if __name__ == '__main__':
torch.multiprocessing.freeze_support()
argp = argparse.ArgumentParser()
argp.add_argument('function',
help="Whether to pretrain, finetune or evaluate a model",
choices=["pretrain", "finetune", "evaluate"])
argp.add_argument('variant',
help="Which variant of the model to run ('vanilla' or 'synthesizer')",
choices=["vanilla", "synthesizer"])
argp.add_argument('pretrain_corpus_path',
help="Path of the corpus to pretrain on", default=None)
# yz: optional argument below
argp.add_argument('--reading_params_path',
help="If specified, path of the model to load before finetuning/evaluation",
default=None)
argp.add_argument('--writing_params_path',
help="Path to save the model after pretraining/finetuning", default=None)
argp.add_argument('--finetune_corpus_path',
help="Path of the corpus to finetune on", default=None)
argp.add_argument('--eval_corpus_path',
help="Path of the corpus to evaluate on", default=None)
argp.add_argument('--outputs_path', default=None)
args = argp.parse_args()
# Save the device
device = torch.nn.current_device() if torch.cuda.is_available() else 'cpu'
block_size = 128
text = open(args.pretrain_corpus_path,encoding="utf8").read()
pretrain_dataset = dataset.CharCorruptionDataset(text,block_size)
mconf = model.GPTConfig(pretrain_dataset.vocab_size, pretrain_dataset.block_size,
n_layer=4, n_head=8, n_embd=256)
if args.variant == 'vanilla':
#pass # TODO [part c]: Make some model here
model = model.GPT(mconf)
elif args.variant == 'synthesizer':
#pass # TODO [part g]: Make some other model here
model = model.GPT(mconf)
# From here on, your code should be identical independent of which
# variant (vanilla or synthesizer) has been chosen.
# From here on, your code should be identical independent of which
# variant (vanilla or synthesizer) has been chosen.
if args.function == 'pretrain':
assert args.pretrain_corpus_path is not None
assert args.writing_params_path is not None
# TODO [part f]:
# - Given:
# 1. A corpus specified in args.pretrain_corpus_path
# 2. An output path args.writing_params_path for the model parameters
# - Goals:
# 1. Pretrain the model on this corpus
# 2. Save the resulting model in args.writing_params_path
# - Make sure to use the following hyperparameters for pretraining:
# max_epochs=650
# batch_size=128
# learning_rate=6e-3
# lr_decay=True
# warmup_tokens=512*20
# final_tokens=200*len(pretrain_dataset)*block_size
# num_workers=4
#raise NotImplementedError
tconf = trainer.TrainerConfig(max_epochs=650, batch_size=128, learning_rate=6e-3,
lr_decay=True, warmup_tokens=512*20, final_tokens=200*len(pretrain_dataset)*block_size,
num_workers=4)
trainer = trainer.Trainer(model, pretrain_dataset, None, tconf)
trainer.train()
torch.save(model.state_dict(),args.writing_params_path)
elif args.function == 'finetune':
#print("I am entering the finetuning!!!!!!!")
assert args.writing_params_path is not None
assert args.finetune_corpus_path is not None
# TODO [part c] [part f]:
# - Given:
# 1. A finetuning corpus specified in args.finetune_corpus_path
# 2. A path args.reading_params_path containing pretrained model
# parameters, or None if finetuning without a pretrained model
# 3. An output path args.writing_params_path for the model parameters
# - Goals:
# 1. If args.reading_params_path is specified, load these parameters
# into the model
# 2. Finetune the model on this corpus
# 3. Save the resulting model in args.writing_params_path
# - Make sure to use the following hyperparameters:
# Hyperparameters for finetuning WITHOUT a pretrained model:
# max_epochs=75
# batch_size=256
# learning_rate=6e-4
# lr_decay=True
# warmup_tokens=512*20
# final_tokens=200*len(pretrain_dataset)*block_size
# num_workers=4
# Hyperparameters for finetuning WITH a pretrained model:
# max_epochs=10
# batch_size=256
# learning_rate=6e-4
# lr_decay=True
# warmup_tokens=512*20
# final_tokens=200*len(pretrain_dataset)*block_size
# num_workers=4
tconf = None
if args.reading_params_path is not None:
model.load_state_dict(torch.load(args.reading_params_path))
tconf = trainer.TrainerConfig(max_epochs=10, batch_size=256, learning_rate=6e-4,
lr_decay=True, warmup_tokens=512*20, final_tokens=200*len(pretrain_dataset)*block_size,
num_workers=4)
else:
tconf = trainer.TrainerConfig(max_epochs=75, batch_size=256, learning_rate=6e-4,
lr_decay=True, warmup_tokens=512*20, final_tokens=200*len(pretrain_dataset)*block_size,
num_workers=4)
#finetune_text = open(args.finetune_corpus_path,encoding="utf8").read()
finetune_dataset = dataset.NameDataset(pretrain_dataset, open(args.finetune_corpus_path,encoding="utf8").read())
trainer = trainer.Trainer(model, finetune_dataset, None, tconf)
#print("Right before the training !!")
trainer.train()
torch.save(model.state_dict(),args.writing_params_path)
#raise NotImplementedError
elif args.function == 'evaluate':
assert args.outputs_path is not None
assert args.reading_params_path is not None
assert args.eval_corpus_path is not None
model.load_state_dict(torch.load(args.reading_params_path))
correct = 0
total = 0
with open(args.outputs_path,'w',encoding="utf8") as fout:
predictions = []
for line in tqdm(open(args.eval_corpus_path,encoding="utf8")):
x = line.split('\t')[0]
x = x + '??'
x = torch.tensor([pretrain_dataset.stoi[s] for s in x],dtype = torch.long)[None,...].to(device)
pred = utils.sample(model,x,32,sample=False)[0]
completion = ''.join([pretrain_dataset.itos[int(i)] for i in pred])
pred = completion.split('??')[1]
predictions.append(pred)
fout.write(pred+'\n')
total,correct = utils.evaluate_places(args.eval_corpus_path, predictions)
if total>0:
print('Correct:{} out of {}: {}%'.format(correct, total,correct/total*100))
else:
print('Predictions written to {}; no targets provided'.format(args.outputs_path))